How to design a robust "seckill" system?

Seckill is the combination of “Second” and “Kill”, which means more than ten thousands of users try to buy a limit number of discounted product at the same time. The system that can handle that presure is called “seckill” system. I believe that many people have seen the seckill system, such as the system of Jingdong or Taobao, and that of the Xiaomi mobile phones.
How is the background of this system implemented? How do we design a high resilience seckill system? What issues should be considered? We will discuss this issue.
One: What issues should be considered for high concurrency scenario
1.1: Oversold problem
Analyzing the business scenario of the seckill, the most important point is the oversold problem. If there are only 100 stocks, but the final oversold is 200, generally speaking, the price of the spike system is relatively low. If oversold, it will seriously affect the company’s property interests. Therefore, the first thing to do is to solve the problem of oversold goods.
1.2: High concurrency
The seckill has the characteristics of short time and large concurrency. The spike lasts only a few minutes. However, in order to create a sensational effect, companies will attract users at a very low price, so there will be a lot of users participating in the rush. There will be a large number of requests coming in in a short period of time. How to prevent the back-end from causing cache breakdown or invalidation due to excessive concurrency, and breaking the database are issues that need to be considered.
1.3: Interface anti-brush
Most of the current spikes will come out for spikes corresponding to the software, this kind of software will simulate the continuous request to the background server, hundreds of times a second are very common, how to prevent this kind of software from repeating invalid requests and preventing continuous requests It also needs our targeted consideration
1.4: url
For ordinary users, all they see is a relatively simple spike page. When the specified time is not reached, the spike button is gray. Once the specified time is reached, the gray button becomes clickable. This part is for Xiaobai users. If you are a user with a little bit of computer skills, you will see the seckill url through F12 to look at the browser’s network, and you can also request the seckill through specific software. Or those who know the spike url in advance can directly realize the spike as soon as they request. We need to consider solving this problem
1.5: Database design
Spike has the risk of destroying our server. If it is used in the same database with our other businesses and coupled with it, it is very likely to involve and affect other businesses. How to prevent this kind of problem from happening? Even if there are downtime or server stuck in the spike, you should try not to affect the normal online business
1.6: Mass request problem
According to the consideration of 1.2, even if the cache is used, it is not enough to deal with the impact of short-term high concurrent traffic. How to carry such a huge amount of visits while providing a stable and low-latency service guarantee is a major challenge that needs to be faced. Let’s calculate an account. If redis caching is used, the QPS that a single redis server can bear is about 4W. If a spike attracts enough users, a single QPS may reach hundreds of thousands, and a single redis is still Not enough to support such a huge amount of requests. The cache will be penetrated and penetrate directly into the DB, thus destroying mysql. A large number of errors will be reported in the background
Two: The design and technical scheme of the spike system
2.1: Database design of spike system
In response to the spike database problem proposed in 1.5, a spike database should be designed separately to prevent the high concurrent access of spike activities from dragging down the entire website. Only two tables are needed here, in fact, there should be several tables. Product table: You can find specific product information, product image, name, usual price, spike price, etc., by linking goods_id, and user table: according to user_id, you can find user nickname and user mobile phone number , Delivery address and other additional information, this specific example will not be given.
2.2: Design of spike url
In order to prevent people with program access experience from directly accessing the backend interface through the order page URL to seckill the goods, we need to make the seckill url dynamic, even those who develop the entire system cannot know the seckill url before the seckill starts.
The specific method is to encrypt a string of random characters as the seckill URL through md5, and then the front-end accesses the background to obtain the specific URL, and the seckill can continue after the background verification is passed.
2.3: Static seckill page
All product descriptions, parameters, transaction records, images, evaluations, etc. are written to a static page. User requests do not need to access the back-end server, do not need to go through the database, and are directly generated on the front-end client, which can minimize the reduction possible. Server pressure.
The specific method can use freemarker template technology to create a web page template, fill in the data, and then render the web page
2.4: Single redis upgrade to cluster redis
Spike is a scenario where you read more and write less, and using redis for caching is perfect. However, considering the cache breakdown problem, we should build a redis cluster and adopt the sentinel mode to improve the performance and availability of redis.
2.5: Use nginx
Nginx is a high-performance web server, its concurrency capacity can reach tens of thousands, while tomcat has only a few hundred. Mapping client requests through nginx and then distributing them to the background tomcat server cluster can greatly improve concurrency.
2.6: Streamline SQL
A typical scenario is when inventory is being deducted. The traditional approach is to check the inventory first and then update. In this case, two SQLs are required, but in fact one SQL can be completed.
You can use this approach: update miaosha_goods set stock =stock-1 where goos_id ={#goods_id} and version = #{version} and sock>0; In this way, you can ensure that the inventory will not be oversold and update the inventory at one time. One thing to note is that optimistic locking of the version number is used here. Compared with pessimistic locking, its performance is better.
2.7: Redis pre-reduction inventory
Many requests come in and need to check the inventory in the background. This is a frequently read scene. You can use redis to pre-reduce the inventory. You can set the value in redis before the spike starts, such as redis.set(goodsId,100), where the pre-released inventory is 100 and the value can be set as a constant). After each order is successfully placed, Integer stock = (Integer)redis.get(goosId); Then determine the value of sock, if it is less than the constant value, subtract 1;
However, note that when canceling, you need to increase the inventory. When increasing the inventory, you must also pay attention to the total inventory number set between (inquiry and deduction of inventory require atomic operations, at this time you can use the lua script) to place an order next time When getting the inventory again, just check it directly from redis.
2.8: Interface current limit
The ultimate essence of spike is the update of the database, but there are a lot of invalid requests. What we ultimately need to do is how to filter out these invalid requests to prevent infiltration into the database. For current limiting, there are many aspects to start:
2.8.1: Front-end current limit
The first step is to limit the current through the front-end. After the user initiates a request after the spike button is clicked, it cannot be clicked in the next 5 seconds (by setting the button to disable). This small measure has a small cost to develop, but it is very effective.
2.8.2: Repeat requests from the same user within xx seconds are directly rejected
The specific number of seconds depends on the actual business and the number of spikes, and is generally limited to 10 seconds. The specific method is to use the redis key expiration strategy. First, for each request, get this from String value = redis.get(userId);
The value is empty or null, indicating that it is a valid request, and then the request is released. If it is not empty, it means it is a repetitive request, and the request is directly discarded. If it works, use redis.setexpire(userId,value,10). The value can be any value. Generally, it is better to put business attributes. This is to set the userId as the key, and the expiration time of 10 seconds (after 10 seconds, the value corresponding to the key) Automatically null)
2.9: token bucket algorithm current limit
There are many strategies for interface current limiting, and we use the token bucket algorithm here. The basic idea of the token bucket algorithm is that each request tries to obtain a token, and the backend only processes requests that hold tokens. We can limit the speed and efficiency of token production. Guava provides RateLimter APIs for us to use. .
The following is a simple example, pay attention to the need to introduce guava:

The idea of the above code is to use RateLimiter to limit our token bucket to produce 1 token per second (the production efficiency is relatively low), and the task is executed 10 times in a loop.
Acquire will block the current thread until the token is acquired, that is, if the task does not acquire the token, it will wait forever. Then the request will be stuck in the time we set before it can go down. This method returns the specific waiting time of the thread.
During the execution of the task, there is no need to wait for the first one, because the token has been produced in the first second. The next task request must wait until the token bucket generates a token before it can continue to execute.
If it is not obtained, it will block (there is a pause in the process). But this method is not very good, because if the user requests on the client side, if there are more, the token will be stuck in the production of the direct background (poor user experience), it will not abandon the task, we need a better one Strategy: If it is not obtained for a certain period of time, the task is directly rejected. Here is another case:
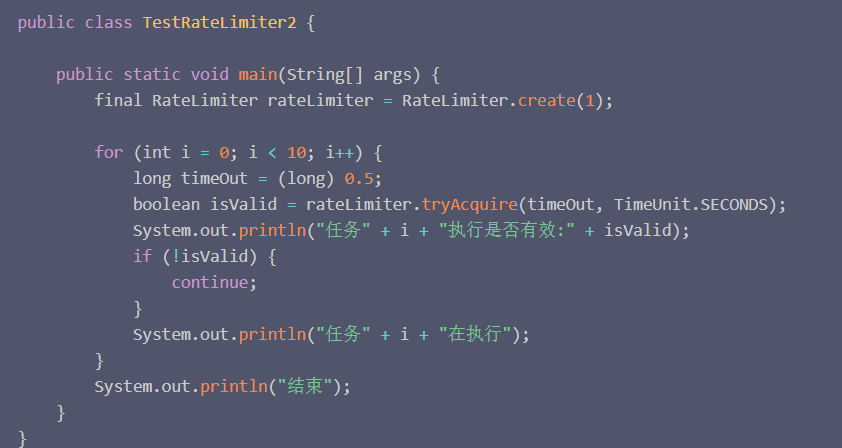
The tryAcquire method is used. The main function of this method is to set a timeout. If it is estimated within a specified time (note that the estimate will not wait for real), if the token can be obtained, it will return true. If you can’t get it, return false.
Then we let the invalid ones skip directly. Here, we set to produce 1 token per second, and let each task try to get the token in 0.5 seconds. If it can’t get it, skip the task directly (put it in the spike environment. Directly discard this request);
Only the first one obtained the token and executed it smoothly. The following basics were directly discarded, because within 0.5 seconds, the token bucket (1 per second) must not be obtained before production and return false.
How efficient is this current limiting strategy? If our concurrent request is a 4 million instant request, the efficiency of token generation is set to 20 per second, and the time for each attempt to obtain a token is 0.05 seconds, then the final test result is that it will only be released each time For about 4 requests, a large number of requests will be rejected, which is the outstanding feature of the token bucket algorithm.
2.10: Asynchronous order placement
In order to improve the efficiency of placing orders and prevent the failure of order placement services. The operation of placing an order needs to be processed asynchronously. The most commonly used method is to use queues. The three most significant advantages of queues are: asynchronous, peak clipping, and decoupling. Rabbitmq can be used here. After the current limit and inventory verification are performed in the background, the valid request flows into this step. Then send to the queue, the queue accepts the message, and asynchronously places the order. After the order is placed, there is no problem with the storage, and the user can be notified by SMS of the success of the spike. If it fails, you can use a compensation mechanism and try again.
2.11: Service degradation
If a server goes down during the spike, or the service is unavailable, backup work should be done. The previous blog introduced service fusing and downgrading through Hystrix, and a backup service can be developed. If the server is really down, a friendly prompt will be sent back to the user directly instead of blunt feedback such as stuck or server error.
Summary
This is how we need to consider when wee need to design a robust seckill system. The process I mentioned can support hundreds of thousands of traffic. If it is tens of millions to break billions, some other features will have to be redesigned. For example, the database sub-database sub-table, the queue is changed to use kafka, redis to increase the number of clusters and other means.
The main purpose of this design is to show how we deal with high-concurrency processing and start trying to solve it. Thinking more and doing more at work can improve our ability level! If there are any errors in this blog, please point them out, it is greatly appreciated.
