Record the entire process of troubleshooting Redis memory growth problem in a production environment!

Recently, the DBA reported to me that an online Redis resources have exceeded the pre-designed capacity, and the capacity has been expanded twice.
The memory growth is still continuing. We hope that the business side will check whether the capacity growth is normal, and if it is normal, restart Evaluate the use of resources, if it is abnormal, we need to find out the problem as soon as possible and provide a solution for processing.
toc
Record the entire process of troubleshooting Redis memory growth in a production environment!
The following is the monitoring situation of usage of the resources, and the number of keys at that time:
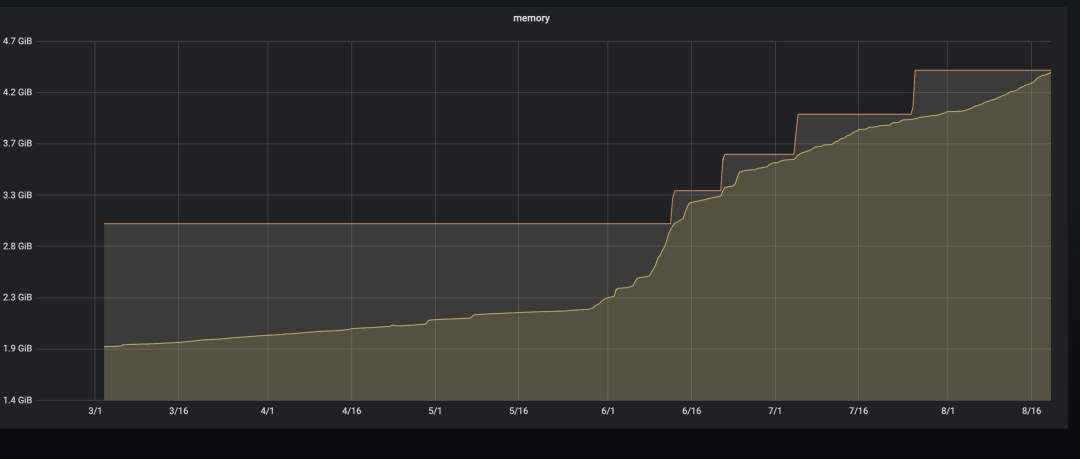
It can be seen from the monitoring that the capacity and keys have increased sharply starting from 1 June. First of all, it is suspected that a malicious swipe operation has caused the number of keys to increase. After a code inspection, it was found that there were indeed code vulnerabilities that caused malicious swipes. After the bug was repaired, it went online. Do you think it’s over here? Naive, otherwise what is the use of writing this article?
But, from the point of view of the request volume of the interface, the situation of brushing is not so obvious. The following is the qps of the interface request:

Continue to investigate the storage design and found that the storage uses the Set structure (because the product did not clearly indicate how many elements are stored under a key at the beginning, the Set is used, which also lays a solid foundation for the subsequent abnormal growth of capacity), and actually each Set Only one element is stored, but the actual capacity has increased by 30M. According to the capacity calculation formula 9w * 14 (key length) * 1 (number of elements) * 10 (element length) = 8.4M, the actual capacity has exceeded nearly 4 times.
At this point, two suspicions have arisen. One is that there is a problem with the amount of memory occupied by the actual stored data, and the other is a problem with the capacity evaluation formula.
Doubt 1: There is a problem with the amount of memory occupied by the actual stored data
After checked the underlying storage structure of Redis Set, it is found that the Set collection is implemented in two ways: an integer set and a dictionary. When the following two conditions are met, the integer set is used; once one of the conditions is not met, the dictionary is used to implement.
All elements in Set are integers, the number of elements in the Set collection is not more than 512 (default 512, you can adjust the size of the collection by modifying the set-max-intset-entries configuration).
After the investigation, according to the normal situation, it should be stored in an integer set, but log on to the machine and use the memory usage key command to check the memory usage and found that the memory usage of a single key has reached 218B.
Incredible, right? Just storing a 10-bit data and the content is numbers, why does it take up so much memory? At this point, we began to wonder if there was a problem with the serialization method that caused the content actually written to Redis to be not a number, so we then checked the serialization method used when the data was actually written. After investigation, it was found that the written value became a hexadecimal data after being serialized. So far, the truth is basically clear, because Redis believes that the stored content is no longer suitable for integer set storage, Change to dictionary storage. After modifying the serialization method, the test adds an element to it, and found that the actual memory usage is only 72B, which is reduced to 1/3 of the original.
Doubt 2: There is a problem with the capacity evaluation formula
The capacity evaluation formula ignores the memory usage of Redis in different situations and calculates it according to the size of the element uniformly, resulting in the actual content usage being too small.
At this point, the abnormal growth of the entire Redis memory capacity can basically come to an end. The next step is to modify the correct serialization and deserialization methods, and then perform the library washing operation. After business investigation, it is found that the current actual use method can be changed to KV structure, so the underlying storage has been transformed.
The library washing process: Online double write logic; Sync historical data; Switch to read new data source; Observe whether the online business is normal; Turn off writing to old storage; Delete old resources; Offline old read and write logic.
There are two choices regarding the storage location of the new data:
The first method is: the old data is normally written to the old resource, and the new data is written to the newly deployed resource. The advantage of this method is that after all the old data is washed into the new resource, then the old resource can be offline; the disadvantage is that the resource configuration needs to be rewritten at the code layer, and the DBA also needs to deploy a new resource.
The second method is: write the old and new data to the old resource, then map the old data to the new data structure, and then wash the old resource in full. The advantage of this method is that there is no need to rewrite a set of resource configuration, and the DBA does not need to deploy new resources. It only needs to expand the memory of the old resource; the disadvantage is that after the full data is washed in, it needs Manually remove old data.
Both options are feasible and can be selected according to your own preferences. We finally chose the second option for data cleaning operations.
Online double write logic:
At the resource storage layer, a switcher (switch) is added for the upstream and downstream read and write operations, and then the logic for reading and writing the new storage is added. After the code test passes, it goes online. We can choose any hot deployment method to modify the flag to control the execution of the code flow. Another point to note is that the modification of the switch state cannot be affected by the project’s online or offline.
Sync historical data:
After the online is completed, export the RDB file of the online library, and analyze all the keys (for the analysis of the RDB file, if there is a dedicated DBA colleague, you can ask the DBA colleague to parse it, if not, you can check the RDB file online. The analysis tool is not difficult); traverse the parsed key in turn, query the old data corresponding to the key, map the old data to the new data structure, and finally write it to the new storage. Regarding synchronizing historical data, you need to make appropriate adjustments according to your actual business scenarios. Only one idea is provided here. The following are the small tools that can be used to wash data. Friends who need it can adjust the code logic appropriately.
Switch to read new data source
After the historical data synchronization is completed, turn off the read operation switch and let it read the newly stored logic
In this step, it should be noted that at this time, only the switch state of the downstream read data is modified to allow it to read the new data source, and the upstream write data switch does not move, and the double write operation is still allowed to prevent downstream switching to the new data source. There is an embarrassing situation in which the new and old data is inconsistent due to the need to roll back.
Observe whether the online business is normal
Switch to the logic of reading the new storage and observe the online business to see if there is any abnormal data complaint by users
Stored write on close
There is no abnormal situation in the online business, and the write operation is also switched to the logic of writing only the new storage, and the writing of the old resources is stopped
Delete old resources
Remove all old keys written on them, and the operation method of removing old data can reuse the data washing process.
Offline old read and write logic
Take all the online read and write logic codes offline, and finally complete the entire process of data cleaning.
Summary
The above is a complete process of troubleshooting and data cleaning in a real production environment. Through the troubleshooting of this issue, the understanding and understanding of the underlying implementation of Redis has been further deepened.
At the same time, what we need to reflect through this accident is that in the face of every line of code written by hand, we need to have a sense of awe and never underestimate it, it may lead to a catastrophic accident if we are not careful.
